
「寝ている間に勝手に記事が増えて、広告収入が入ってきたら…」
エンジニアなら一度は夢見る「ブログの完全自動化」。 私もその甘美な夢を追いかけ、GitHub ActionsとOpenAI (GPT-4o) を駆使して、ニュース収集から執筆、ブログ記事投稿、Xへの拡散までを完全自動化するシステムを構築しました。
技術的には完璧でした。サーバー代もかからず(完全無料)、毎日決まった時間に記事が投稿される。ログを見れば「Success」の文字が並ぶ。
しかし、結論から言うとこの運用は止めました。
なぜ、エンジニアの夢である「全自動化」は失敗したのか? そして、そこから得られた「本当に稼ぐための半自動化戦略」とは?
実際に稼働させていたPythonコードとYAMLファイルをすべて公開(コピペOK)しながら、現代におけるエンジニアの生存戦略について解説します。
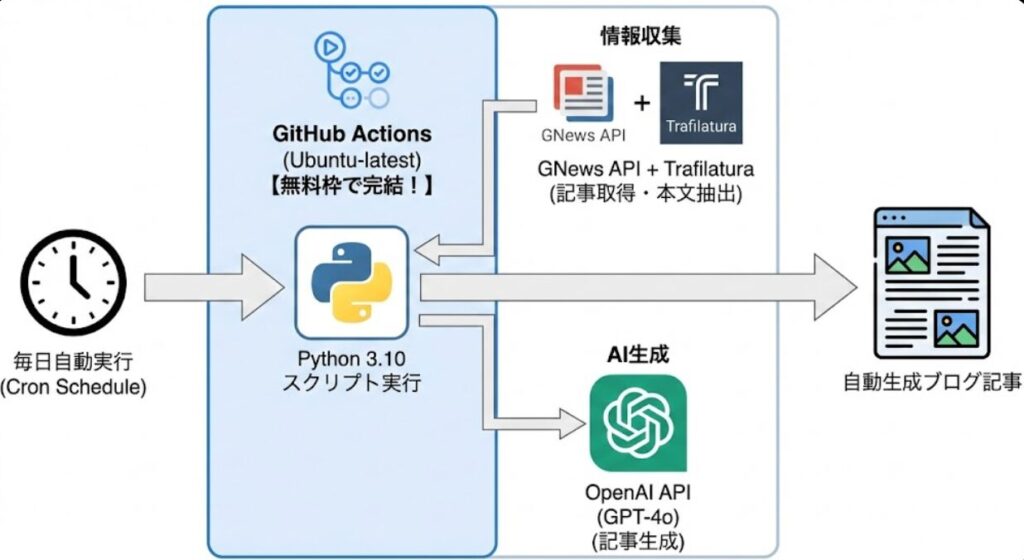
技術構成:サーバーレスで0円運用の仕組み
まずは、私が構築した「自動投稿システム」のアーキテクチャを紹介します。 AWSのLambdaやEC2を使わず、GitHub Actionsの無料枠だけで完結させているのがポイントです。
- インフラ: GitHub Actions (Ubuntu-latest)
- トリガー: Cronスケジュール(毎日自動実行)
- 言語: Python 3.10
- 生成AIモデル: OpenAI API (GPT-4o)
- 情報源: GNews API + Trafilatura
実際のWorkflowファイル (.github/workflows/main.yml)
GitHub Actionsの設定は非常にシンプルです。リポジトリのSecretsにAPIキーなどを登録し、Pythonスクリプトを叩くだけです。
Auto Post to WordPress and Twitterのコード
name: Auto Post to WordPress and Twitter
on:
schedule:
– cron: ‘0 23 * * *’ # 毎日8時(JST)に実行(UTC+9)
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
– name: Checkout repo
uses: actions/checkout@v3
– name: Set up Python
uses: actions/setup-python@v4
with:
python-version: ‘3.10’
– name: Install dependencies
run: |
pip install requests openai feedparser requests_oauthlib trafilatura markdown PyYAML
– name: Run auto_post script
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
PEXELS_API_KEY: ${{ secrets.PEXELS_API_KEY }}
WP_URL: ${{ secrets.WP_URL }}
WP_USER: ${{ secrets.WP_USER }}
WP_APP_PASSWORD: ${{ secrets.WP_APP_PASSWORD }}
X_API_KEY: ${{ secrets.X_API_KEY }}
X_API_KEY_SECRET: ${{ secrets.X_API_KEY_SECRET }}
ACCESS_TOKEN: ${{ secrets.ACCESS_TOKEN }}
ACCESS_TOKEN_SECRET: ${{ secrets.ACCESS_TOKEN_SECRET }}
GNEWS_API_KEY: ${{ secrets.GNEWS_API_KEY }}
run: |
python auto_post.py
【コピペOK】自動投稿Pythonスクリプトの全貌
肝心のPythonコードがこちらです。 単にGPTに書かせるだけでなく、「人間味」を出すために工夫したポイントがあります。
工夫点1:ニュースサイトからの高精度な本文抽出
BeautifulSoupではなく、本文抽出に特化したライブラリtrafilaturaを採用しています。これでサイドバーの広告やナビゲーションを除外し、記事の純粋な中身だけをAIに渡しています。
# 記事取得部分の抜粋
def get_articles(keyword, max_articles=5):
# ... (前略) ...
for article in raw_articles:
downloaded = trafilatura.fetch_url(article_url)
extracted = trafilatura.extract(downloaded) # ここが高精度!
if extracted and len(extracted) >= 1000: # 短すぎる記事は除外
results.append({"content": extracted, "url": article_url})工夫点2:「ぎょうざ語」によるキャラ付け
AIっぽさを消すために、記事の最後にエセ中国人風のキャラクター「ぎょうざ」によるコメントを強制的に挿入していました。今見ると涙ぐましい努力です(笑)。
def add_human_column(article_md: str) -> str:
prompt = """
以下の記事の文末に、約120文字で楽観的、ポジティブな一言を追加してください。
【条件】
- 語尾は「アル」「アルね」などエセ中国人風にする。
- 意外性、考察を含めて「人間らしさ」があること
"""
# ... GPT-4oにリクエスト ...ソースコード全文
以下に全コードを置いておきます。ライブラリさえ入れれば、APIキーの設定だけで今すぐ動きます。
ソースコード全文
import feedparser
import openai
import requests
from base64 import b64encode
import random
import string
from requests_oauthlib import OAuth1
from datetime import datetime, timedelta
import trafilatura
import os
import yaml
import markdown
OPENAI_API_KEY = os.environ['OPENAI_API_KEY']
PEXELS_API_KEY = os.environ['PEXELS_API_KEY']
WP_URL = os.environ['WP_URL']
WP_USER = os.environ['WP_USER']
WP_APP_PASSWORD = os.environ['WP_APP_PASSWORD']
X_API_KEY = os.environ['X_API_KEY']
X_API_KEY_SECRET = os.environ['X_API_KEY_SECRET']
ACCESS_TOKEN = os.environ['ACCESS_TOKEN']
ACCESS_TOKEN_SECRET = os.environ['ACCESS_TOKEN_SECRET']
GNEWS_API_KEY = os.environ['GNEWS_API_KEY']
client = openai.OpenAI(api_key=OPENAI_API_KEY)
# カテゴリとハッシュタグ構成
CATEGORY_CONFIG = {
10: {"name": "SNS速報/アップデート情報", "hashtags": ["#新機能", "#SNS速報", "#最新SNS", "#アップデート"]},
11: {"name": "マーケティング戦略・事例", "hashtags": ["#SNSマーケ", "#バズ事例", "#広告戦略", "#話題化"]},
12: {"name": "収益化/成功例", "hashtags": ["#インフルエンサー", "#副業", "#収益化", "#クリエイター"]},
13: {"name": "SNS炎上/バズ分析", "hashtags": ["#炎上", "#バズ分析", "#SNSトラブル", "#誤解"]},
14: {"name": "SNSツール・活用術", "hashtags": ["#使い方", "#効率化", "#SNS活用", "#便利ツール"]},
15: {"name": "編集部コラム", "hashtags": ["#未来予測", "#トレンド解説", "#考察", "#深掘り"]}
}
def generate_slug():
return f"nextsns-{datetime.now().strftime('%Y%m%d')}-{''.join(random.choices(string.ascii_lowercase + string.digits, k=4))}"
def guess_mime_type(filename):
ext = filename.lower().split('.')[-1]
return {
"jpg": "image/jpeg",
"jpeg": "image/jpeg",
"png": "image/png",
"webp": "image/webp"
}.get(ext, "application/octet-stream")
def get_articles(keyword, max_articles=5):
url = f"https://gnews.io/api/v4/search?q={keyword}&country=us&lang=en&sortby=popularity&max={max_articles}&token={GNEWS_API_KEY}"
try:
response = requests.get(url)
response.raise_for_status()
raw_articles = response.json().get('articles', [])
except Exception as e:
print(f"❌ GNews API取得失敗: {e}")
return []
results = []
for article in raw_articles:
article_url = article.get('url')
try:
downloaded = trafilatura.fetch_url(article_url)
extracted = trafilatura.extract(downloaded)
if extracted and len(extracted) >= 3000:
results.append({
"content": extracted,
"url": article_url,
"length": len(extracted)
})
except Exception as e:
print(f"⚠️ 記事取得スキップ ({article_url}): {e}")
continue
# 長さ順にソート(長い順)
results.sort(key=lambda x: x['length'], reverse=True)
# 必要に応じてlengthを削除して返す
return [{"content": r["content"], "url": r["url"]} for r in results]
def load_prompt_for_category(category_id, yaml_path='prompts.yaml'):
with open(yaml_path, encoding='utf-8') as f:
return yaml.safe_load(f).get(category_id, {}).get('prompt', '')
def append_reference_section(article_md, article_url, source_name="出典元"):
if "参考元記事" in article_md:
return article_md
return article_md.strip() + f"\n\n---\n\n### 🔗 参考元記事\n- {source_name}: [{article_url}]({article_url})\n"
def rewrite_article(article_md: str) -> str:
prompt = f"""
以下のMarkdown形式のブログ記事を、読者の感情と知的好奇心を刺激するように自然にリライトしてください。
- セクションのつながりをスムーズに
- 難しい単語は使わず、口語を用いて親しみがある記事にすること
- 記者視点・仮説・比喩を含めて、AIらしくない文体で書き直してください
記事:
{article_md}
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは優秀な編集者です。"},
{"role": "user", "content": prompt}
],
temperature=0.6
)
return response.choices[0].message.content.strip()
def add_human_column(article_md: str, category_id: int) -> str:
prompt = f"""
以下の記事の文末に、この記事に対して約120文字で楽観的、ポジティブな一言の意見を追加してください。
【条件】
- 敬語は使わず、語尾は「アル」「アルね」「アルよ」などエセ中国人風にする。
- 意外性、考察を含めて「人間らしさ」があること
- 参考元記事のセクションより前に挿入する
【カテゴリID】{category_id}
記事本文:
{article_md}
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは個性的な考えを持つライターです。"},
{"role": "user", "content": prompt}
],
temperature=0.7
)
return article_md.strip() + f"\n\n---\n\n### 個人的なひとこと\n[speech title='ぎょうざ']{response.choices[0].message.content.strip()}[/speech]\n"
def generate_japanese_article(articles, category_id):
prompt = load_prompt_for_category(category_id)
if not prompt:
raise ValueError(f"カテゴリID {category_id} にプロンプトなし")
content_all = "".join([f"【記事{i+1}】\n{a['content']}\n\n" for i, a in enumerate(articles)])
full_prompt = f"{prompt}\n\n【参考記事】\n{content_all}"
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは読者を惹きつけるプロのブロガーです。"},
{"role": "user", "content": full_prompt}
],
temperature=0.7
)
lines = response.choices[0].message.content.splitlines()
title, article, mode = "", "", None
for line in lines:
if line.startswith("title:"):
title = line.replace("title:", "").strip()
elif line.startswith("article:"):
mode = "article"
elif mode == "article":
article += line + "\n"
article = rewrite_article(article)
article = add_human_column(article, category_id)
article = append_reference_section(article.strip(), article_url=articles[0]['url'])
return title, article
def generate_summary_meta(article_md: str) -> tuple:
prompt = f"""
以下のブログ記事本文から、meta description(SEO向けの簡潔で魅力的な説明)を生成してください:
---
{article_md}
"""
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "system", "content": "あなたはSEOに詳しいライターです。"}, {"role": "user", "content": prompt}]
)
return response.choices[0].message.content.strip()
def fetch_pexels_image(query):
url = f"https://api.pexels.com/v1/search?query={query}&per_page=5"
headers = {"Authorization": PEXELS_API_KEY}
photos = requests.get(url, headers=headers).json().get("photos", [])
for p in photos:
if (p['width'] / max(p['height'], 1)) >= 1.3:
return p['src'].get("large2x") or p['src'].get("large")
return photos[0]['src'].get("large2x") if photos else None
def upload_image_and_get_media_id(url):
token = b64encode(f"{WP_USER}:{WP_APP_PASSWORD}".encode()).decode()
img = requests.get(url).content
fname = url.split("/")[-1].split("?")[0]
headers = {
"Authorization": f"Basic {token}",
"Content-Disposition": f"attachment; filename={fname}",
"Content-Type": guess_mime_type(fname)
}
res = requests.post(f"{WP_URL}/media", headers=headers, data=img)
return res.json().get("id") if res.status_code == 201 else None
def post_to_wordpress(title, content, category_id, keyword):
meta_desc = generate_summary_meta(content)
token = b64encode(f"{WP_USER}:{WP_APP_PASSWORD}".encode()).decode()
headers = {"Authorization": f"Basic {token}", "Content-Type": "application/json"}
img_url = fetch_pexels_image(keyword)
media_id = upload_image_and_get_media_id(img_url) if img_url else None
content_html = markdown.markdown(content, extensions=["extra"])
print("📄 meta_desc:", meta_desc)
post = {
"title": title,
"slug": generate_slug(),
"content": f"<meta name='description' content='{meta_desc}'>\n" + content_html,
"status": "publish",
"date": datetime.now().isoformat(),
"categories": [category_id],
"excerpt": meta_desc
}
if media_id:
post["featured_media"] = media_id
res = requests.post(f"{WP_URL}/posts", headers=headers, json=post)
if res.ok:
link = res.json().get("link")
print("✅ 投稿成功:", link)
# アイキャッチ画像に alt を設定
if media_id:
requests.post(f"{WP_URL}/media/{media_id}", headers=headers, json={
"alt_text": title
})
# post_to_x(meta_desc, link, category_id)
else:
print("❌ 投稿失敗:", res.text)
def post_to_x(summary, post_url, category_id):
hashtags = CATEGORY_CONFIG.get(category_id, {}).get("hashtags", ["#SNS"])
selected = random.sample(hashtags, min(2, len(hashtags)))
tweet = f"{summary} \n\n{' '.join(selected)}\n🔗 {post_url}"
auth = OAuth1(X_API_KEY, X_API_KEY_SECRET, ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
response = requests.post("https://api.twitter.com/2/tweets", auth=auth, json={"text": tweet})
print("✅ X投稿成功!" if response.ok else f"❌ X投稿失敗: {response.status_code} {response.text}")
def select_random_category_and_keyword():
keywords = {
10: [ # SNS速報/アップデート情報
"Twitter update",
"Instagram features",
"TikTok algorithm",
"Threads app",
"YouTube update"
],
11: [ # マーケティング戦略・事例
"social media marketing",
"influencer campaign",
"TikTok marketing",
"Instagram engagement",
"social media ads"
],
12: [ # 収益化/成功例
"creator monetization",
"OnlyFans earnings",
"YouTube income",
"TikTok affiliate",
"Instagram bonus"
],
13: [ # SNS炎上/バズ分析
"social media scandal",
"influencer controversy",
"TikTok backlash",
"misinformation X",
"cancel culture"
],
14: [ # SNSツール・活用術
"social media tools",
"AI content tools",
"Instagram scheduling",
"TikTok analytics",
"Chrome social extensions"
],
15: [ # 編集部コラム
"future of social media",
"AI in social media",
"Web3 networks",
"online communities",
"digital identity"
]
}
cid = random.choice(list(keywords.keys()))
return cid, random.choice(keywords[cid])
def main():
cid, keyword = select_random_category_and_keyword()
articles = get_articles(keyword)
if not articles:
print("❌ 記事取得失敗")
return
print("📄 元原稿:", articles)
title, content = generate_japanese_article(articles, cid)
print("📄 原稿生成:", title)
post_to_wordpress(title, content, cid, keyword)
if __name__ == "__main__":
main()プロンプト全文
10: # SNS速報/アップデート情報
description: “SNSの新機能・UI変更・アルゴリズム変更など速報的な内容”
prompt: |
以下の英語ニュース記事をもとに、日本語で速報性のある読みやすいブログ記事を作成せよ。
【目的】
- 海外SNSのアップデートや新機能をいち早く日本ユーザーに届ける
- なぜ重要か、ユーザーにどう影響するかを簡潔に説明する
- Google AdSense 審査に通過するよう、オリジナリティと信頼性を重視する
【構成】
- 導入としてニュースの概要を簡単に説明
- 基礎知識の解説
- ニュースの詳しい解説
- ニュースから考えられる今後の展望
【執筆条件】
- 人間が書いたような自然な文体であること(GPTらしさを排除)
- 単なる要約ではなく、考察や影響分析を含めること
- 人名は英語のままにすること
- 難しい用語や概念は調べて補足すること
【出力形式】
title: SEOに強く、32文字以内の共感や驚きを誘うキャッチーなタイトル
article: Markdown形式で記事全体を記述(導入・本文・まとめ)11: # マーケティング戦略・事例
description: “SNSを活用した企業・ブランドのマーケティング成功例やプロモーション分析”
prompt: |
以下の英語ニュース記事をもとに、日本語で読み応えのあるマーケティング分析記事を作成せよ。
【目的】
- 海外のマーケ事例から日本ユーザーが学べる記事にする
- なぜ成功したのか、どこが工夫されていたのかを深掘りする
- Google AdSense に適した記事品質と信頼性を担保する
【構成】
- 導入としてニュースの概要を簡単に説明
- 基礎知識の解説
- ニュースの詳しい解説
- ニュースから考えられる今後の展望
【執筆条件】
- 人間が語りかけるような自然な文体
- 成功の構造や再現性に焦点を当てる
- 人名は英語のままにすること
- 難しい用語や概念は調べて補足すること
【出力形式】
title: SEOに強く、32文字以内のキャッチーで再現性のある成功分析系タイトル
article: Markdown形式(導入・内容解説・成功要因・学び)12: # 収益化/成功例
description: “個人やインフルエンサーによるSNS活用での収益化成功事例や方法論”
prompt: |
以下の英語ニュース記事をもとに、SNSで収益化に成功した個人・チームの事例を紹介せよ。
【目的】
- 再現可能なノウハウを読み手に提供する
- オリジナリティと信頼性をもとに収益化への示唆を与える
- Google AdSense に通過しうる品質を担保する
【構成】
- 導入としてニュースの概要を簡単に説明
- 基礎知識の解説
- ニュースの詳しい解説
- ニュースから考えられる今後の展望
【執筆条件】
- 感情やモチベーションにも触れる
- 再現性や工夫点を抽出する
- 人名は英語のままにすること
- 難しい用語や概念は調べて補足すること
【出力形式】
title: SEOに強く、32文字以内の個人がマネしたくなるような行動喚起型タイトル
article: Markdown形式(導入・方法・成果・応用)13: # SNS炎上/バズ分析
description: “SNSで話題になった炎上・バズ事例の背景や構造を分析”
prompt: |
以下の英語ニュース記事をもとに、SNSで起きた炎上・バズの構造や背景を考察する記事を作成せよ。
【目的】
- 炎上や拡散の構造を読み解く
- 感情・倫理・SNS心理を掘り下げる
- Google AdSenseの信頼性基準を満たすよう事実確認と出典を明記する
【構成】
- 導入としてニュースの概要を簡単に説明
- 基礎知識の解説
- ニュースの詳しい解説
- ニュースから考えられる今後の展望
【執筆条件】
- 中立的かつ深い観察視点を持つ
- 読者に問いかけを含めて思考を促す
- 人名は英語のままにすること
- 難しい用語や概念は調べて補足すること
【出力形式】
title: SEOに強く、32文字以内のSNS心理や炎上構造を表す分析的タイトル
article: Markdown形式(概要・背景・構造分析・教訓)14: # SNSツール・活用術
description: “SNS運用に便利なツール紹介やハウツー・Tipsのまとめ”
prompt: |
以下の英語ニュース記事やレビューをもとに、SNS運用に役立つツールやノウハウを紹介せよ。
【目的】
- 実用的で役立つ情報を読者に届ける
- 信頼できるレビュー形式でツールの魅力を伝える
- Google AdSenseに適した構成と透明性を意識する
【構成】
- 導入としてニュースの概要を簡単に説明
- 基礎知識の解説
- ニュースの詳しい解説
- ニュースから考えられる今後の展望
【執筆条件】
- 親しみやすく信頼できる文体
- 体験的・比較的な視点を含める
- 人名は英語のままにすること
- 難しい用語や概念は調べて補足すること
【出力形式】
title: SEOに強く、32文字以内のツール名と用途が明確な実用的タイトル
article: Markdown形式(導入・ツール概要・機能・活用法)15: # 編集部コラム
description: “編集者による独自視点のコラムや未来予測・月次のまとめ記事”
prompt: |
以下の英語ニュース記事をもとに、SNSに関する洞察や未来予測を含む深いコラム記事を作成せよ。
【目的】
- 読者の思考を刺激し、知的な関心を引く
- 個人的視点・社会的意義を盛り込む
- Google AdSenseのポリシーに沿い、信頼性を高める
【構成】
- 導入としてニュースの概要を簡単に説明
- 基礎知識の解説
- ニュースの詳しい解説
- ニュースから考えられる今後の展望
【執筆条件】
- 感情・問いかけ・社会性を含めた文体
- 人名は英語のままにすること
- 難しい用語や概念は調べて補足すること
【出力形式】
title: SEOに強く、32文字以内の抽象度が高くても意味が通る洞察的タイトル
article: Markdown形式(導入・考察・社会との接点・まとめ)なぜ「完全自動化」は失敗したのか?
技術的には完璧に動作しました。エラーも出ず、毎朝8時には新しい記事が公開されていました。 しかし、私は運用開始から1ヶ月でこのシステムを停止しました。
理由はシンプルで、「価値のないゴミ記事を量産するだけだったから」です。
理由1:熱量がない
「ぎょうざ語」でキャラ付けしても、結局はニュースの要約です。そこには私の「体験談」も「一次情報」も「苦悩」もありません。Googleはこれを「質の低いコンテンツ(コピーコンテンツ)」と見なします。
理由2:信頼性の欠如
AIは平気で嘘をつきます(ハルシネーション)。完全自動投稿だとファクトチェックができないため、デマを拡散するリスクと常に隣り合わせでした。「エンジニアブログ」として、間違った技術情報を垂れ流すのは致命的です。
理由3:虚無感
ログを見て「お、今日も投稿されたな」と思うだけで、読者からの反応は皆無。エンジニアリングとしては楽しいですが、メディア運営としては死んでいました。
結論:「AI 半自動化」こそが正解
この失敗から学んだのは、「AIは『下書き』まで。魂を入れるのは人間」という鉄則です。
現在は完全自動化を廃止し、「AIに構成案と下書きを作らせて、人間がリライトして投稿する」というフローに切り替えました。 結果として、記事の品質は担保されつつ、執筆時間は3分の1に短縮できています。
技術を「資産」に変えよう
今回公開したコードは、「完全自動化」としては失敗でしたが、「情報収集ツール」や「Xへの自動投稿Bot」としては非常に優秀な部品になります。
こうしたスクリプトを自分の手元で動かして検証するためには、GitHub Actionsだけでなく、自由に使えるLinux環境(VPS)や、テスト用のWordPress環境を持っておくと便利です。 私は開発検証用とブログ本番用を兼ねて、ConoHa WINGを使っています。
エンジニアなら「自分でサーバー立ててなんぼ」と思うかもしれませんが、「面倒な保守は金で解決して、コードを書く・記事を書く時間に充てる」のが、賢いエンジニアの生存戦略です。

試すだけなら一日のランチ代より安い金額で1ヶ月以上サーバーを使うことができます。
トライすることは経験として資産となります。

おまけ:Blueskyへの投稿機能を追加する
最近、X(旧Twitter)からの移行先として注目されているBluesky。 実はBlueskyはAPIが非常に使いやすく、エンジニアにとって遊びがいのあるSNSです。

上記のPythonスクリプトに以下の関数を追加し、main()関数の中で呼び出せば、ブログ更新と同時にBlueskyへも自動投稿できます。
Bluesky自動投稿コード
# Blueskyへの投稿用コード
from atproto import Client
def post_to_bluesky(text, image_path=None):
try:
BSKY_USER = os.environ['BSKY_USER'] # secretsに登録したID
BSKY_PASS = os.environ['BSKY_PASS'] # secretsに登録したアプリパスワード
client = Client()
client.login(BSKY_USER, BSKY_PASS)
if image_path:
with open(image_path, 'rb') as f:
img_data = f.read()
# 画像付き投稿
client.send_image(text=text, image=img_data, image_alt='Generated Image')
else:
# テキストのみ投稿
client.send_post(text=text)
print("✅ Bluesky投稿成功")
except Exception as e:
print(f"❌ Bluesky投稿失敗: {e}")

